ServerBase Blog
Mit der Inbetriebnahme unseres Datacenters in Lupfig ist es erstmals möglich, eine georedundante Serverinfrastruktur mit Virtual Datacenter aufzubauen. Alle Ressourcen werden datacenterübergreifend und zentral in einem Portal, dem vCloud Director, verwaltet. Der gesamte Technologiestack stammt von VMware und garantiert einen zuverlässigen Betrieb und ein konsistentes Datenmanagement.
Hochverfügbarkeit ist eine grosse und oftmals kostenintensive Thematik, zu der sich unterschiedliche Ansätze etabliert haben. Die Virtualisierung von Ressourcen und Netzwerken brachte in den letzten Jahren entscheidende Vorteile, welche wirtschaftliche und sogleich robuste Lösungen erlauben. Die nachfolgenden Ansätze zu Georedundanz bieten im Störungsfall unterschiedliche Ausfallzeiten mit mehr oder weniger Komplexität.
Die Datensicherung ist die klassische „Einstiegsvariante“ zur Erfüllung von minimalen Verfügbarkeitsanforderungen kann gleichermassen positive oder negative Gefühle wecken kann. Das Backup ist oftmals der Retter in der Not, sofern sich denn der System-Administrator gut darum gekümmert hat und alle Daten vom gewünschten Zeitpunkt auch tatsächlich wiederherstellbar sind. Mittels dem in Virtual Datacenter integrierten Veeam Backup Service wird diese Aufgabe zum Kinderspiel, weil Sie für Tests innert Minuten Ihre VMs als Kopie wiederherstellen, testen ob der Restore korrekt funktioniert hat und sie anschliessend wieder löschen. Die zusätzlich benötigten Ressourcen bezahlen Sie nur für den jeweiligen Testzeitraum.
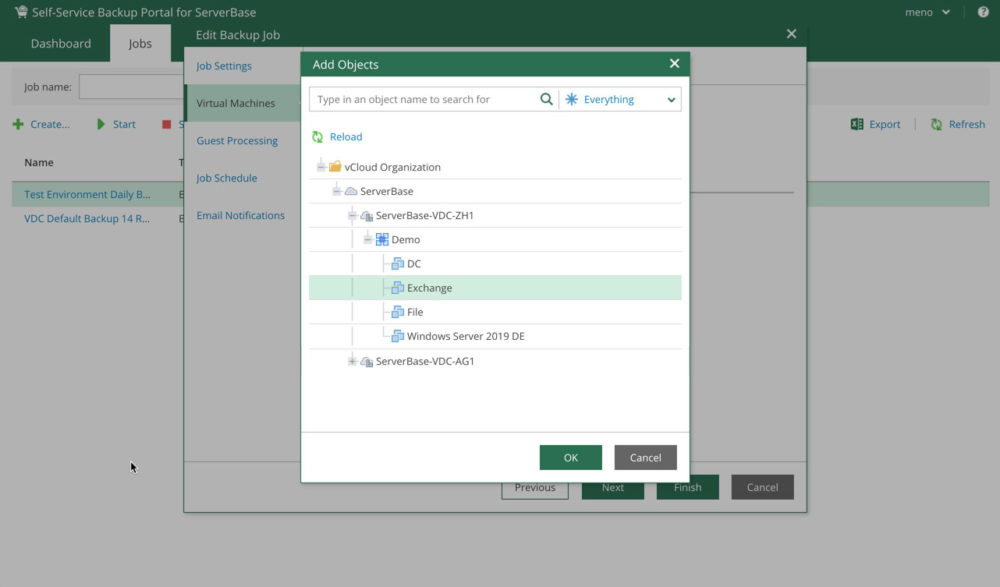
Sichern von VMs in Virtual Datacenter mit dem Veeam Self-Service Backup Portal
Möchten Sie die integrierte Backupfunktionalität zur Sicherstellung eines georedundanten Betriebs nutzen, sichern Sie Ihre Serversysteme nach einem beliebigen Zeitplan ins sekundäre Datacenter mittels Veeam Backup Self-Service Portal. Bei einem Ausfall stellen Sie das letzte Backup manuell im sekundären Datacenter wieder her und der Betrieb kann fortgesetzt werden.
Empfehlung: Organisationen mit kleinem IT-Budget, denen tiefe Betriebskosten wichtiger sind als Verfügbarkeit. Ein Systemausfall von 1 bis 2 Tagen ist vertretbar.
Bei höheren Anforderungen bauen Sie Ihre Serverinfrastruktur im sekundären Datacenter nach und realisieren die Redundanz auf Applikationsebene. Diese Architektur erfordert, dass alle redundant auszulegenden Services die entsprechende Funktionalität mitbringen. Dies ist beispielsweise bei Active Directory, DFS Fileservern, Microsoft Exchange, Microsoft SQL, Oracle RDBMS und Citrix Virtual Apps der Fall. Die Services organisieren dabei die Replikation der Daten und den Failover selbstständig, sodass bei einem Ausfall die Server im sekundären Datacenter den aktiven Betrieb übernehmen.
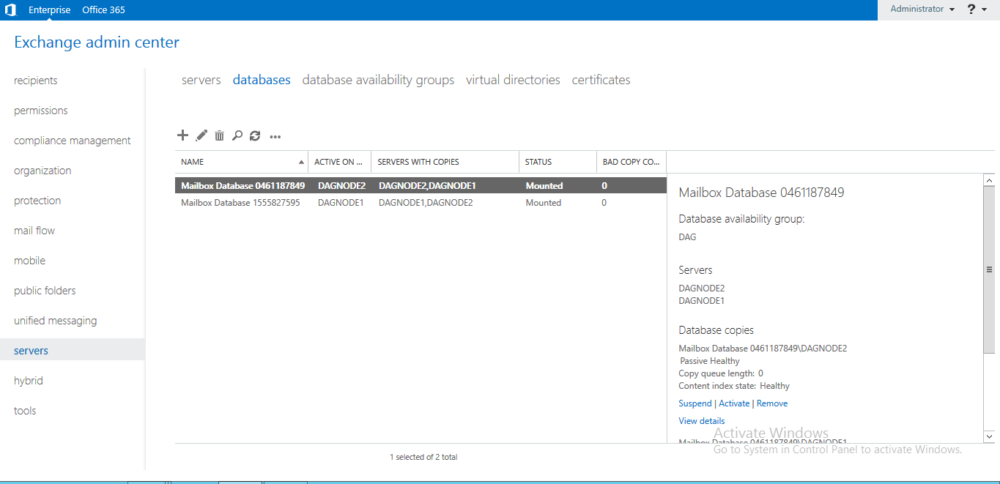
Redundante Konfiguration der Exchange Datenbank auf Applikationsebene
Empfehlung: Organisationen mit sehr hohen Verfügbarkeitsanforderungen und genügend IT-Budget, um die Architektur zu realisieren und die Serverinfrastruktur doppelt zu betreiben.
Nun kommen wir zu der dritten, von mir klar bevorzugten Variante. Nutzen Sie die in Virtual Datacenter integrierte Availability-Funktionalität, um mit wenig Aufwand eine fortlaufende Replikation von VMs ins sekundäre Datacenter zu realisieren. Bei einem Ausfall steuern Sie den Failover mit einem Klick im vCloud Director oder über die integrierte API. Alle VMs werden daraufhin im sekundären Datacenter fortgesetzt und die Services stehen umgehend wieder zur Verfügung. Die gesamte Konfiguration erfolgt grafisch in vCloud Director und erfordert keinerlei Spezialknowhow.
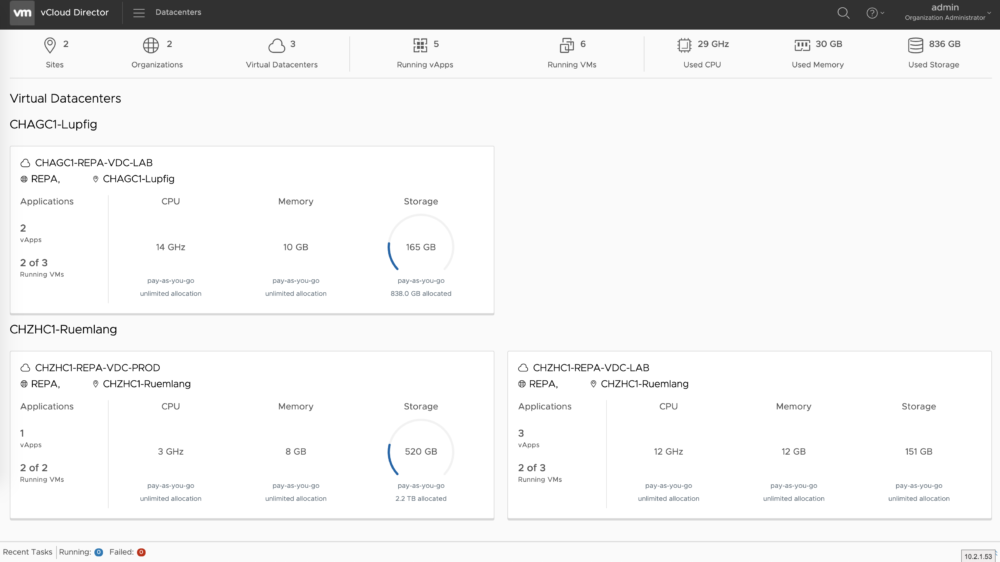
Virtual Datacenter mit beiden Datacenter-Standorten zur Konfiguration von Disaster Recovery
Empfehlung: Organisationen mit hohen Verfügbarkeitsanforderungen, welche die Georedundanz ihrer Systeme mit einfachen und wirtschaftlichen Mitteln sicherstellen möchten.
Die Gegenüberstellung zeigt, dass die Availability Features verglichen mit den Kosten die beste Leistung liefern. Jede Organisation einer gewissen Grösse sollte darüber nachdenken, ihre Services georedundant aufzubauen. Mit Virtual Datacenter und den integrierten Availability Features ist das kostengünstig und einfach zu realisieren.
 Produkt-Assistent
Produkt-Assistent

Unser Produkt-Assistent hilft Ihnen, das für Sie passende Produkt zu finden.
