ServerBase Blog
With the launch of our data center in Lupfig it is possible to build a redundant server infrastructure with Virtual Datacenter. All resources are managed centrally across both data centers in our portal, the vCloud Director. The entire technology stack comes from VMware and guarantees reliable operation and consistent data management.
In the following three-part blog post series I will explain the concept and functionality of the availability features integrated in Virtual Datacenter and show how they can be used to design georedundant services. High availability is a large and often cost-intensive topic for which different approaches have been established. For instance the virtualization of resources and networks has brought game changing advantages in the recent years, which allow reliable and still economical solutions. As an introduction in the first part I would like to present the approaches to High Availability and Disaster Recovery, which I recommend to our customers based on their needs. In the second part I will start with the implementation of a georedundant and highly available infrastructure design with Virtual Datacenter.
Data backup is the “entry-level” for meeting minimum availability requirements and can raise either positive or negative feelings. A backup is often saving the bacon in an emergency, as long as the system administrator has taken good care of it and all data from the desired time is actually recoverable. With the Veeam Backup Service integrated in Virtual Datacenter this task becomes child’s play, because you can restore your VMs with a single click as a copy for tests within minutes, test whether the restore has worked correctly and then delete them again. You only pay for the additional resources required for the respective testing period.
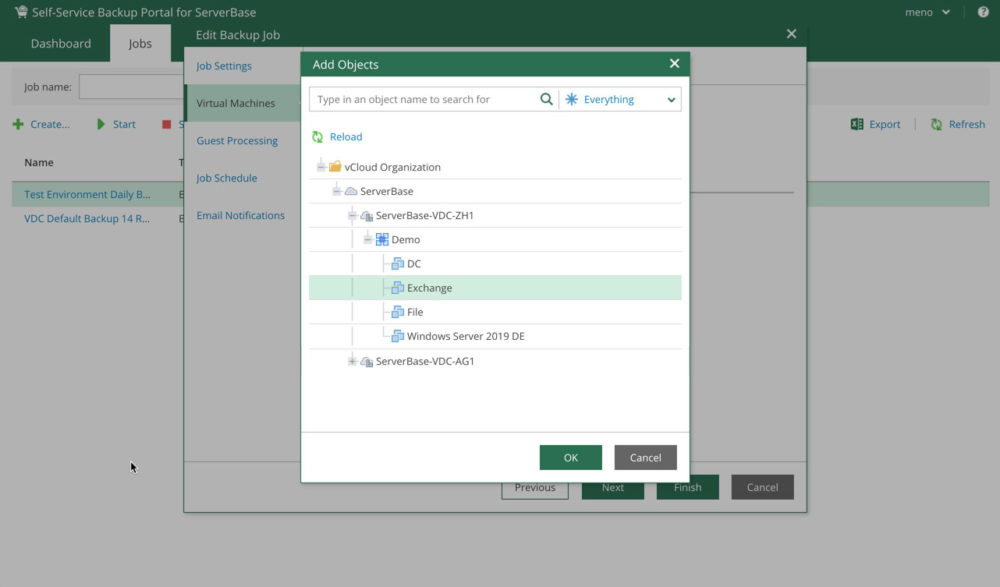
Backup VMs in Virtual Datacenter with the Veeam Self-Service Backup Portal
If you want to use the integrated backup functionality to ensure georedundant operation, back up your server systems to the secondary data center according to a given schedule using the Veeam Backup Self-Servie Portal. In case of a failure, you restore the last backup manually in the secondary data center and the operation can be continued.
Recommendation: Organizations with a small IT budget for which low operating costs are more important than availability. A system failure of 1 to 2 days is acceptable.
For higher requirements, you build your server infrastructure in the secondary data center and implement redundancy at application level. This architecture requires that all services with redundancy requirements have the appropriate functionality. For example the following services support this: Active Directory, DFS file servers, Microsoft Exchange, Microsoft SQL, Oracle RDBMS and Citrix Virtual Apps. The services organize replication of the data and automatic failover independently, so that in the event of a failure, the servers in the secondary data center take over active operation.
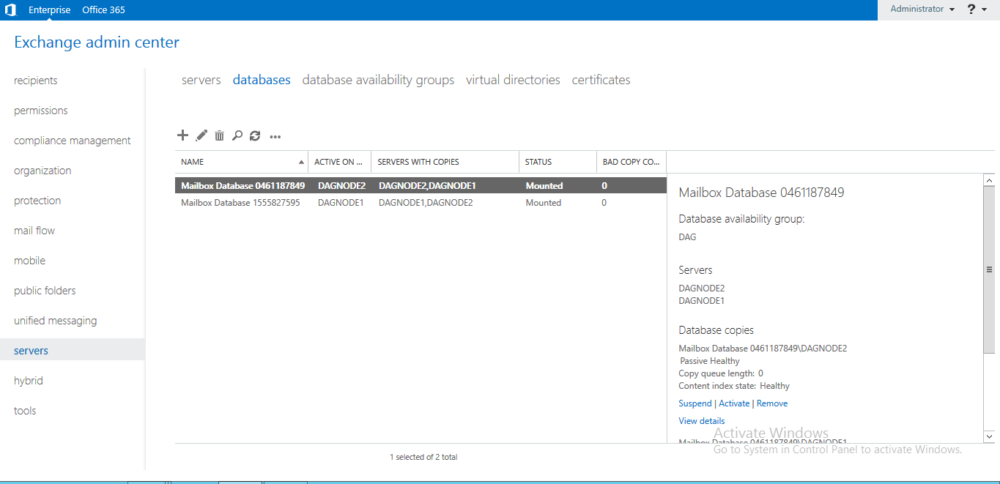
Redundant configuration of the Exchange database at application level
Recommendation: Organizations with very high availability requirements and sufficient IT budget to implement the architecture and to operate the server infrastructure twice.
Let’s dive in to the third option, which I clearly prefer. You can use the availability functionality integrated in Virtual Datacenter to implement continuous replication from VMs to the secondary datacenter with little effort. In the event of a failure, you can control the failover with a single click in vCloud Director or via the integrated API. All VMs are then continued in the secondary data center and the services are immediately available again. The entire configuration is done graphically in vCloud Director and requires no special know-how.
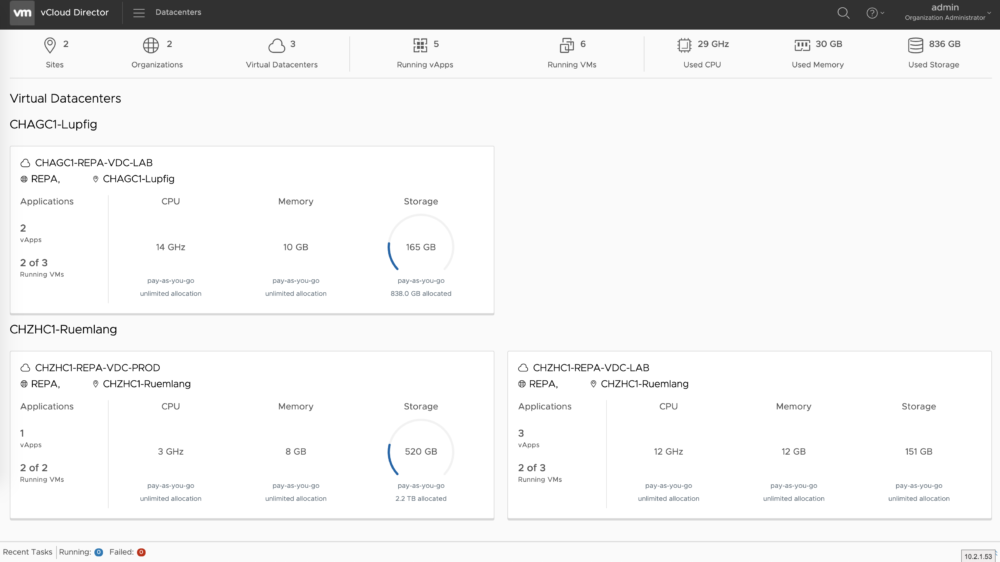
Virtual Datacenter with both datacenter locations for configuring Disaster Recovery
Recommendation: Organizations with high availability requirements that want to ensure georedundancy of their systems with simple and economical means.
The comparison of the three methods shows that the availability features deliver the best performance compared to the costs. Every organization of a certain size should think about building its services georedundant. With Virtual Datacenter and the integrated Availability features this is cost effective and easy to realize. How, you will learn in the second part of this blogpost series next week.
 Product Assistant
Product Assistant

Our product assistant helps you to find the right products.
